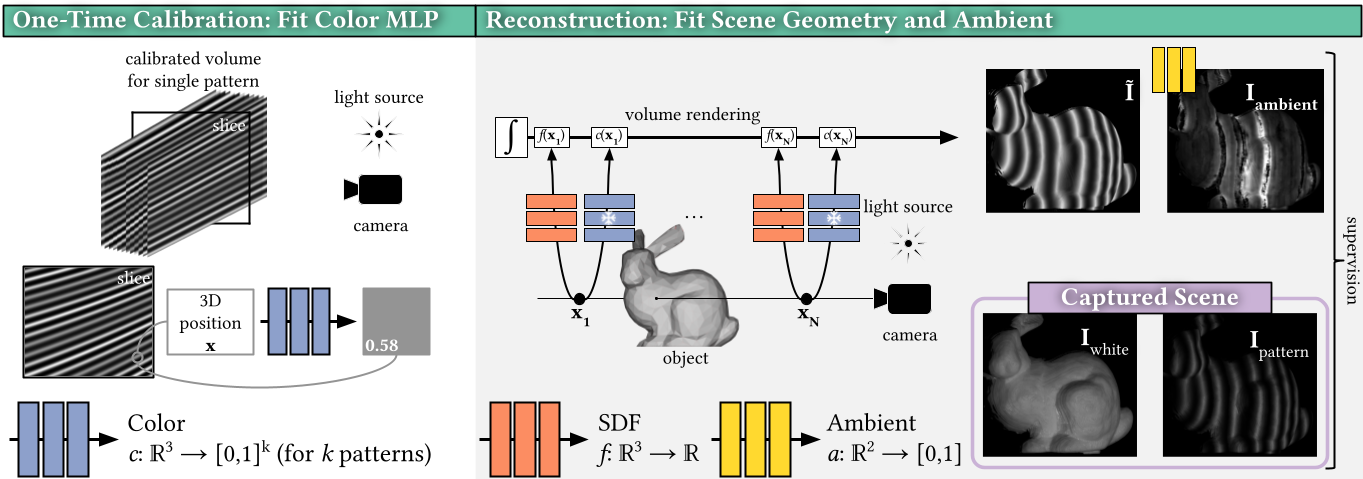
We propose NeLU3D, a neural inverse structured light method that foregoes the explicit modeling of the projector. With as few as four monochromatic images (or two RGB images), our approach extracts accurate surfaces and normal orientation using arbitrary light sources, such as extremely low-cost projectors or high-speed analog projectors with a fixed pattern for slow-motion capture. We show scans of over twenty-five objects of different shapes, sizes, reflectances, and textures to demonstrate the feasibility and quality of our method in a handful of projector-camera configurations. We also showcase sub-millimeter accurate results with suboptimal patterns, where previous methods fail or recover 3D shapes covered by noisy outliers.